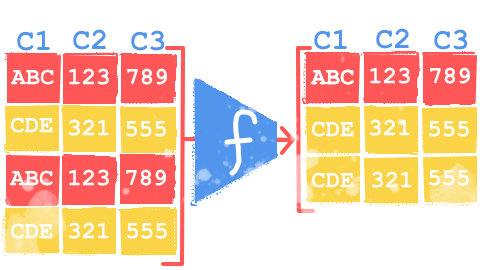
Duplicate Rows
In [1]:
# Identifying and Removing Duplicate Rows
import pandas as pd
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'],
'age': [25, 30, 35, 25, 30],
'city': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Los Angeles']
}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
duplicates = df.duplicated()
print("\nDuplicate Rows:")
print(duplicates)
df_no_duplicates = df.drop_duplicates()
print("\nDataFrame after removing duplicates:")
print(df_no_duplicates)
Original DataFrame:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 Alice 25 New York
4 Bob 30 Los Angeles
Duplicate Rows:
0 False
1 False
2 False
3 True
4 True
dtype: bool
DataFrame after removing duplicates:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
In [2]:
# Removing Duplicates Based on Specific Columns
import pandas as pd
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'],
'age': [25, 30, 35, 25, 30],
'city': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Los Angeles']
}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
df_no_duplicates_name = df.drop_duplicates(subset=['name'])
print("\nDataFrame after removing duplicates based on 'name':")
print(df_no_duplicates_name)
Original DataFrame:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 Alice 25 New York
4 Bob 30 Los Angeles
DataFrame after removing duplicates based on 'name':
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
In [3]:
# Keeping the Last Occurrence of Duplicate Rows
import pandas as pd
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'],
'age': [25, 30, 35, 25, 30],
'city': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Los Angeles']
}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
df_no_duplicates_last = df.drop_duplicates(keep='last')
print("\nDataFrame after removing duplicates, keeping the last occurrence:")
print(df_no_duplicates_last)
Original DataFrame:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 Alice 25 New York
4 Bob 30 Los Angeles
DataFrame after removing duplicates, keeping the last occurrence:
name age city
2 Charlie 35 Chicago
3 Alice 25 New York
4 Bob 30 Los Angeles
In [4]:
# Counting Duplicate Rows
import pandas as pd
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'],
'age': [25, 30, 35, 25, 30],
'city': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Los Angeles']
}
df = pd.DataFrame(data)
print("Original DataFrame:")
print(df)
duplicate_count = df.duplicated().sum()
print("\nNumber of duplicate rows:")
print(duplicate_count)
Original DataFrame:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
3 Alice 25 New York
4 Bob 30 Los Angeles
Number of duplicate rows:
2