Article 1: Foundations of Sentiment Analysis in Text and Voice
Introduction to Opinion Mining
Sentiment Analysis (SA), often termed opinion mining, is the computational study of people's opinions, sentiments, emotions, and attitudes toward entities such as products, services, or events (Liu, 2012). As humans, we find speech and text to be the most natural ways to express these internal states. Traditionally, SA focused on categorizing text into facts (objective) and opinions (subjective). However, as computational power and algorithmic sophistication have grown, the field has expanded into a complex, multimodal discipline capable of interpreting nuanced human behavior across various media (Zhang et al., 2024).
The Core Components of an Opinion: The Quintuple Model
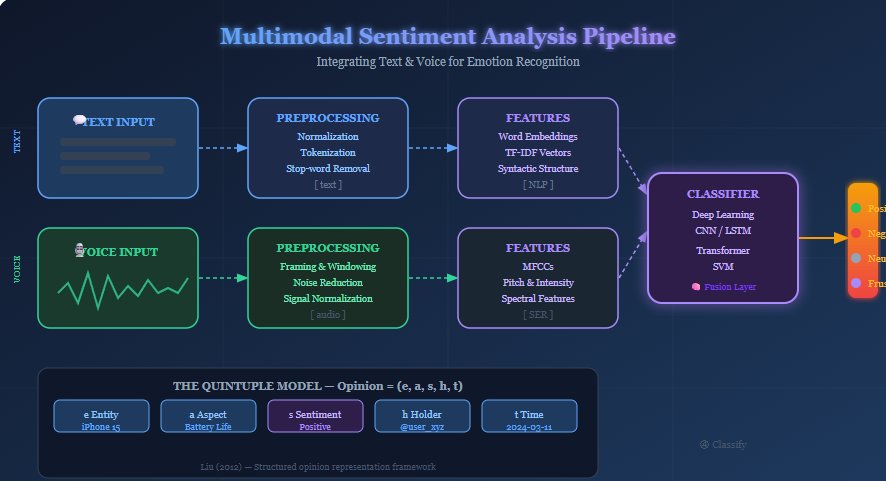
To transform unstructured natural language into structured data, researchers utilize a quintuple model. This framework ensures that sentiment is not analyzed in a vacuum but is linked to specific targets and contexts. According to Liu (2012), an opinion is defined by five essential components:
- Entity (ei) — The target object (e.g., a smartphone, a movie, or a political candidate).
- Aspect (aij) — The specific feature of the entity being evaluated (e.g., the "battery life" of the phone or the "script" of the movie).
- Sentiment (sijkl) — The polarity (positive, negative, or neutral) or the intensity of the emotion (e.g., "very happy" vs. "content").
- Opinion Holder (hk) — The person or organization expressing the view, which is vital for identifying bias or authority.
- Time (tl) — When the opinion was expressed, allowing for longitudinal analysis of how public perception shifts.
Text vs. Voice Analysis: The Paralinguistic Divide
The methodology for extracting these components differs significantly between text and voice. While text sentiment analysis relies on lexical and semantic content—the "what" is said—Speech Emotion Recognition (SER) focuses on paralinguistic features, or the "how" it is said (Schuller, 2018).
Text analysis evaluates word sequences and syntactic structures to determine if a sentence is subjective or objective. In contrast, voice analysis identifies emotional states—such as anger, happiness, or sadness—by analyzing acoustic signals irrespective of the words used. For example, a speaker might say "That is just great" with heavy sarcasm. A text-based model might misclassify this as positive due to the word "great," while a voice-based model would detect the biting tone through variations in pitch and intensity (Akçay & Oğuz, 2020). Voice analysis is critical for making human-machine communication feel more natural and responsive (Lech et al., 2020).
The Multimodal Sentiment Pipeline
The integration of text and audio streams creates a comprehensive processing flow. By combining the semantic depth of text with the emotional nuance of voice, modern systems achieve higher accuracy in intent recognition. The standard pipeline follows these stages:
- Input Data: Acquisition of raw text strings or audio waveforms (WAV/MP3).
- Preprocessing: For text, this involves normalization and tokenization; for audio, it involves framing and windowing the signal.
- Feature Extraction: Textual features are represented via word embeddings; audio features are represented via Mel-Frequency Cepstral Coefficients (MFCCs).
- Classification: Advanced models like Support Vector Machines (SVM) or Deep Learning architectures (CNN/LSTM) categorize the data.
- Output: The final determination of sentiment polarity or specific emotional states (e.g., "Frustrated").
References
- Akçay, M. B., & Oğuz, K. (2020). Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Communication, 116, 56–76.
- Lech, M., Stolar, M., Best, C., & Bolia, R. (2020). Real-time speech emotion recognition using a pre-trained image classification network. Frontiers in Computer Science, 2, 14.
- Liu, B. (2012). Sentiment analysis and opinion mining. Morgan & Claypool Publishers.
- Schuller, B. W. (2018). Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Communications of the ACM, 61(5), 90–99.
- Zhang, S., Yang, Y., Chen, C., Zhang, X., Leng, Q., & Zhao, X. (2024). Deep learning-based multimodal emotion recognition from audio, visual, and text modalities. Expert Systems with Applications, 237, 121692.